The Qwen-VL series has consistently been the most performant VLM in the open-source community. After a year of waiting, the PR for Qwen3-VL has finally arrived 🎉
There will be two models: a dense variant and a MoE variant. Given how well MoE is performing and that Qwen3 has a MoE variant, this is unsurprising. Based on the PR, we can see the following changes from Qwen2.5-VL.
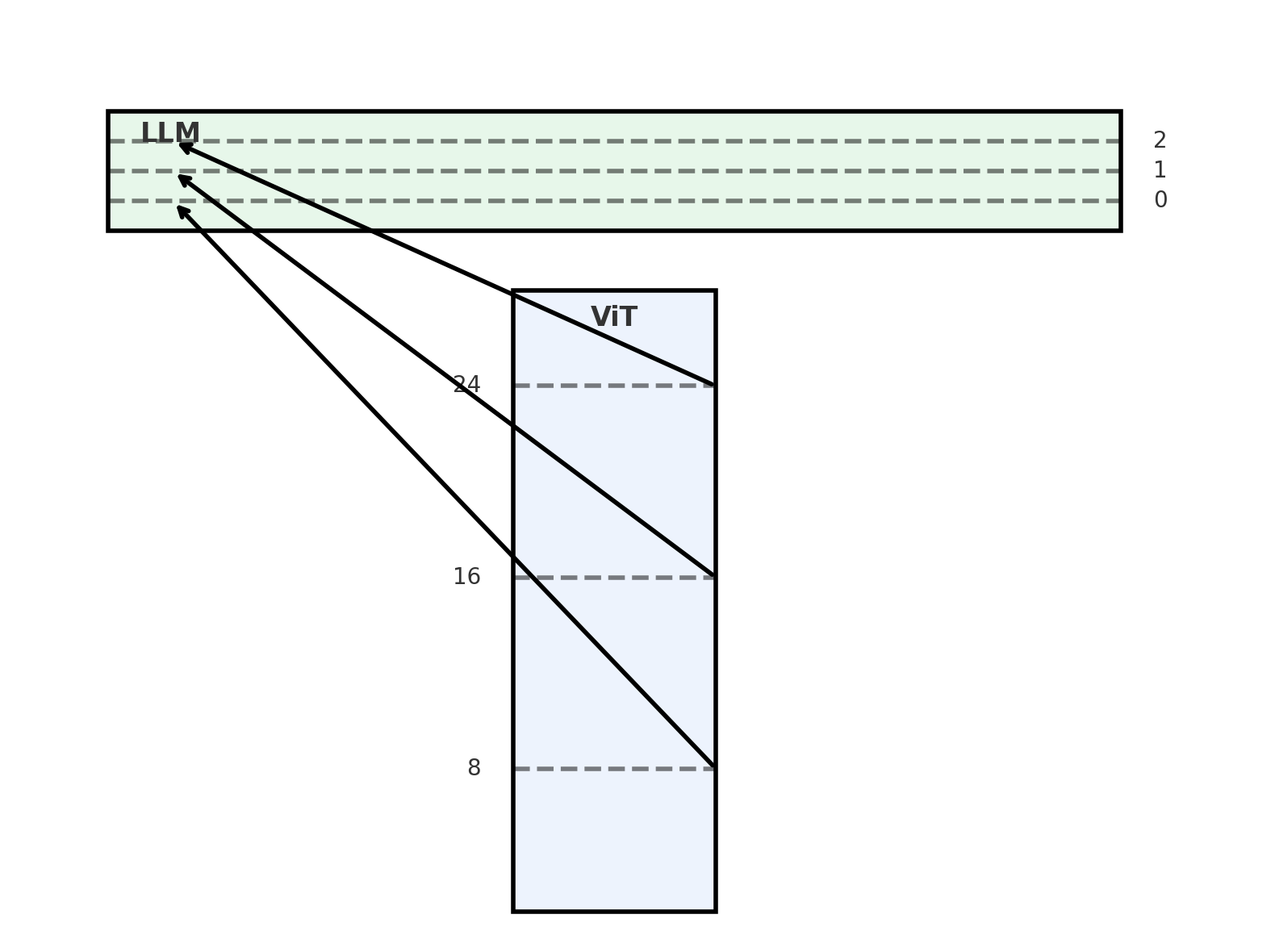
This is the largest algorithmic change. Instead of using ViT’s final output for LLM input, they extract visual representations from several layers. The visual features are extracted from 3 layers by default (8, 16, 24).
These features are then added to the LLM’s hidden state in the first few layers. They call this Deepstack. This intuitively creates a long residual connection to the ViT and helps improve visual representation learning.
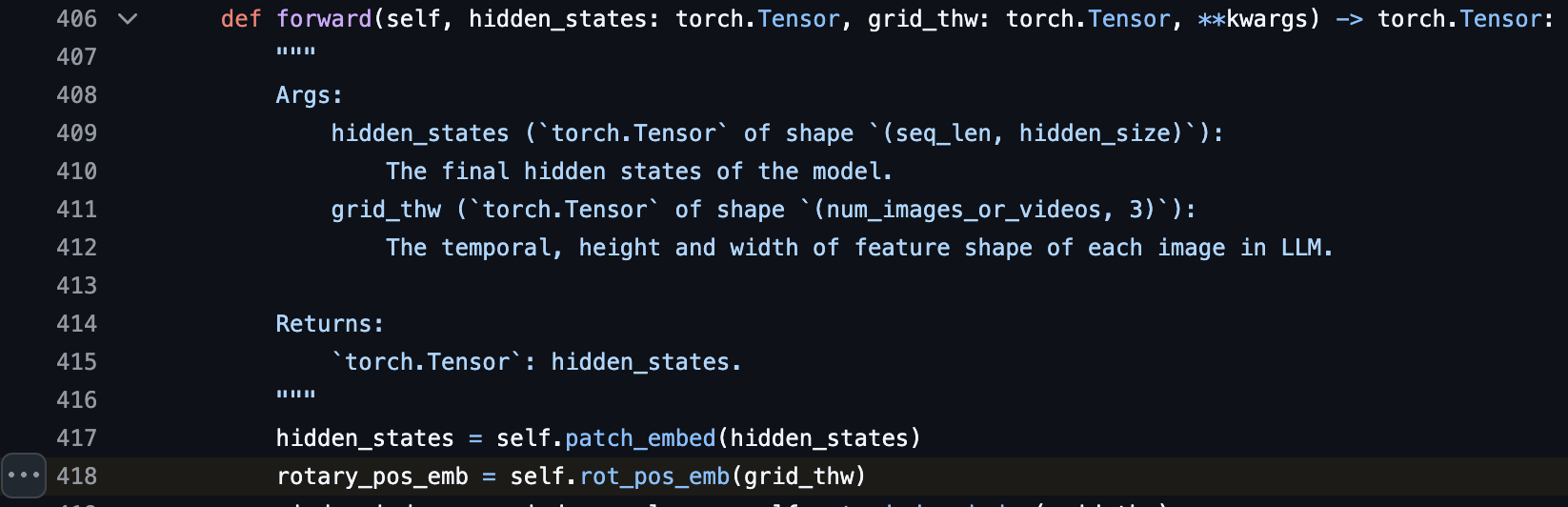
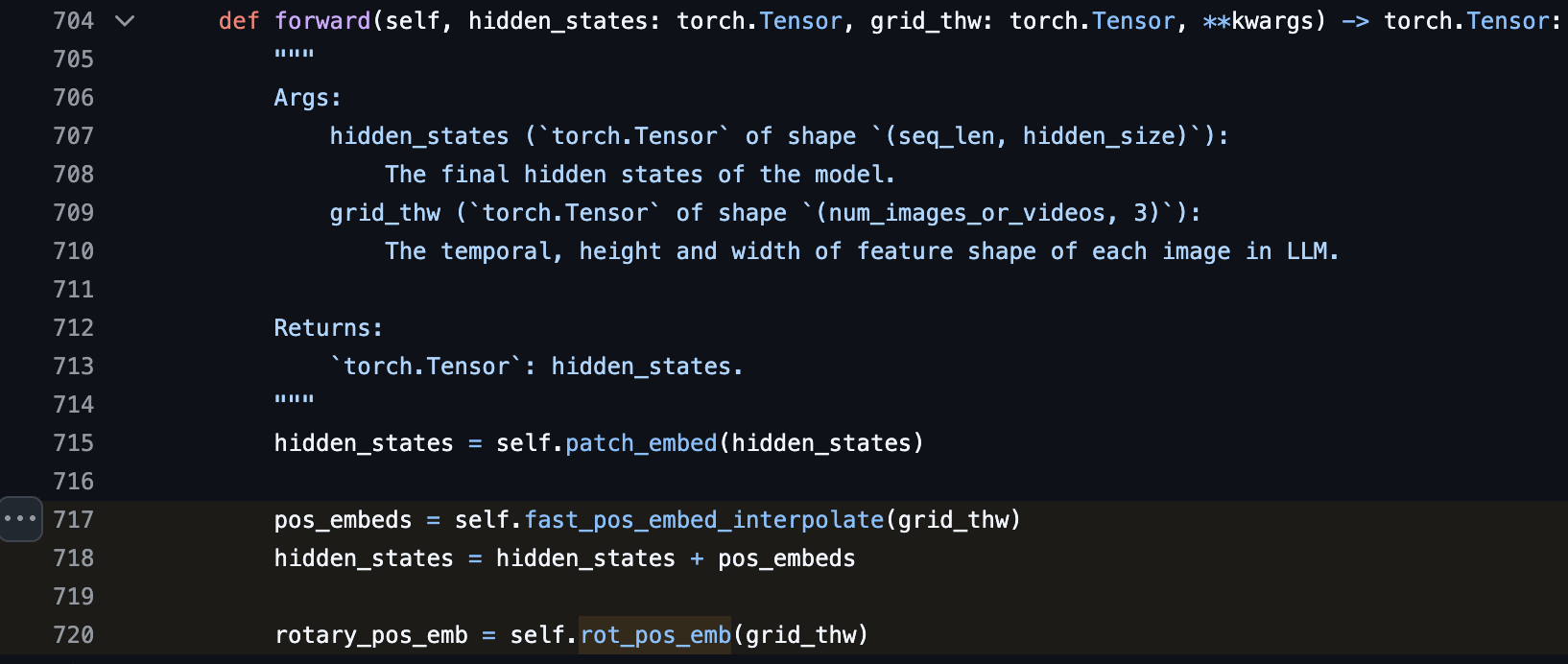
Based on the code, it appears that Qwen3-VL still pretrains its own ViT instead of using off-the-shelf models like SigLip. The biggest change in the ViT is the position embedding!
In the previous Qwen2.5-VL, the position embedding for each vision patch is relative, implemented with RoPE.
For Qwen3-VL, the position embedding for vision patches is a combination of absolute learnable embedding (similar to how DINO works) + relative position embedding. The absolute learnable embedding is added to the hidden state and then RoPE is applied. By having these learnable absolute position embeddings, the grounding capability of the VLM improves. Previously, the same technique was used in Keye-VL 1.5.
| Qwen2.5-VL | Qwen3-VL |
|---|---|
| Relative position embedding (RoPE) for vision patches | Absolute learnable position embedding + RoPE |
|
|
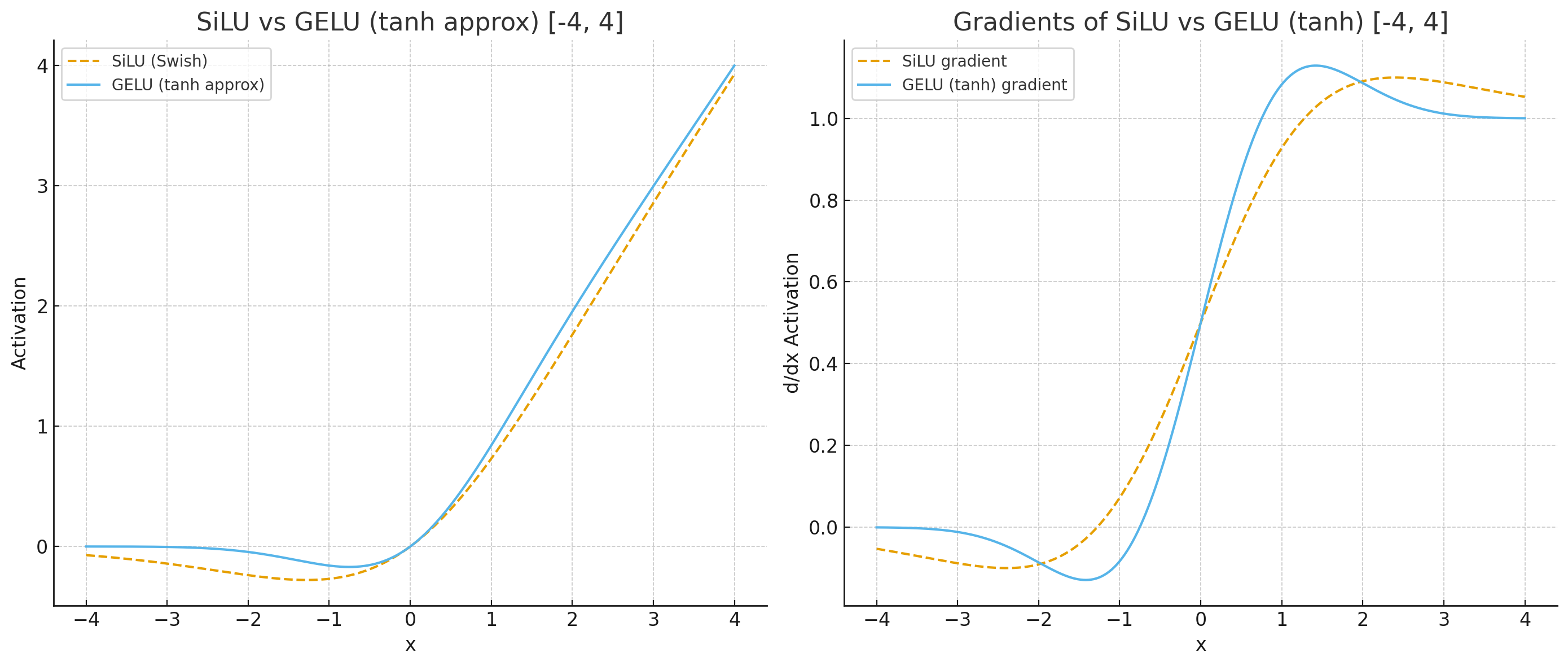
Qwen3-VL switches from silu to gelu_pytorch_tanh. The comparison is shown below. GeLU has much steeper gradients near 0.
| Qwen2.5-VL | Qwen3-VL |
|---|---|
SiLU
SiLU(x) = x · σ(x)
|
GELUtanh
GELUtanh(x) = 0.5 · x · (1 + tanh(√(2/π) · (x + 0.044715 x³)))
|
| Fewer FLOPs | More FLOPs |
| Smoother gradients near 0, taper off slower. | Sharper gradients near 0, taper off faster. |
|
|
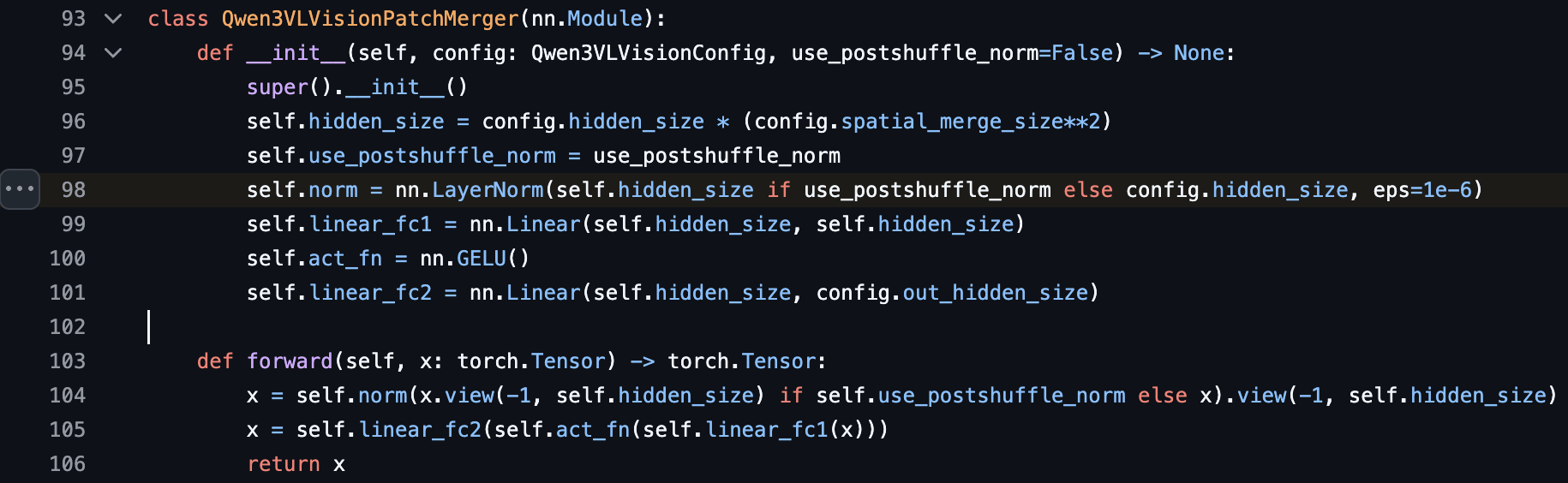
One interesting design in the new ViT is that it has post-pixelshuffle normalization after patch merging. An additional layer norm is applied after the pixel shuffle operation. Apparently, different vision patches can have very distinct distributions, and this operation is needed to make the output smoother.
Qwen2.5-VL introduced MRoPE, which is a 3D RoPE that encodes the temporal dimension in the first index (modulated by the FPS), and the width/height in the remaining two indices.
In Qwen3-VL, this has changed to explicit text based timestamp tokens before the video frames, i.e., <t1> <vision_start> <frame1> <vision_end> <t2> <vision_start> <frame2> <vision_end> .... This provides absolute temporal information compared to the previous version.
If the input is A cat <frame1> <frame2> <frame3> where each frame has one vision patch, the comparison is as follows:
| Qwen2.5-VL | Qwen3-VL |
|---|---|

|

|
Such a design will improve the temporal localization capability of VLM.